AI(人工知能)が急速に社会に浸透するに伴い、AIの利用が人間の権利に悪影響を及ぼす可能性を認識し、適切に対応することが社会的課題となっています。
租税の領域でもAIが影響を及ぼしつつあります。例えば、納税者が業務にAIを利用したり、AI・ロボットに課税する議論があります(例えば、泉絢也「AI・ロボット税の議論を始めよう : 「雇用を奪うAI・ロボット」から「野良AI・ロボット」まで」千葉商大紀要59巻1号(2021))。
課税当局自身がAIを使うことを前提とした議論がなされることがあります(例:OECDの税務行政3.0「Tax Administration 3.0: The Digital Transformation of Tax Administration」)。
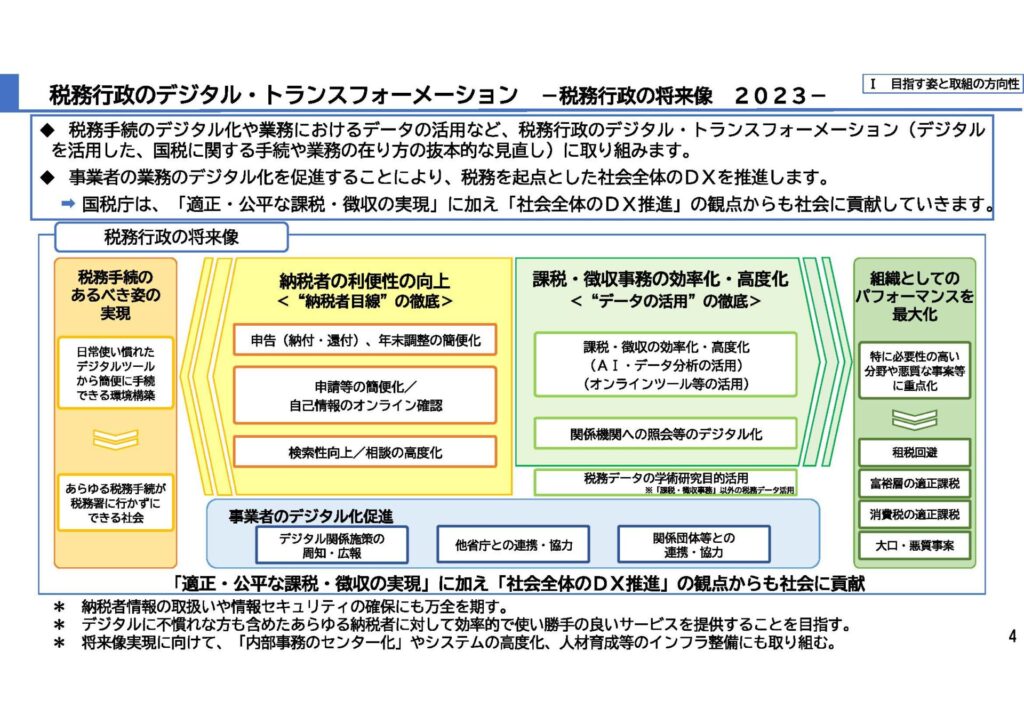
2017年には、国税庁も「スマート税務行政」を打ち出し、租税行政へのAIの活用を打ち出し、実際に運用が始まっています。その後、令和5年6月に発表された「税務行政のデジタル・トランスフォーメーション―税務行政の将来像 2023―」という資料からもAIの活用を推進する国税庁の意向とを読み取ることができます。
拙稿「税務調査で活用進むAIの本当の脅威」週刊エコノミストオンラインもご覧ください。



筆者自身も国税庁が業務にAIを利用すること自体は賛成です。
しかしながら、法的な観点からいうと、利点ばかりが強調されており、起こり得る法的問題点について何ら触れられていません。では、どような法的問題点が存在するのか?
この記事では、泉絢也「税務行政におけるAI(人工知能)・機械学習アルゴリズムの利用と法的問題―調査選定システムの検討を中心として―」千葉商大論叢59巻1号(2021)と同「AIの行政利用の法的問題と国税庁が遵守すべきAI諸原則」税研37巻2号(2021)に基づいて、簡単に国税庁によるAI(人工知能)の利用と問題点を整理します。
想定する調査選定(調査必要度判定)システム
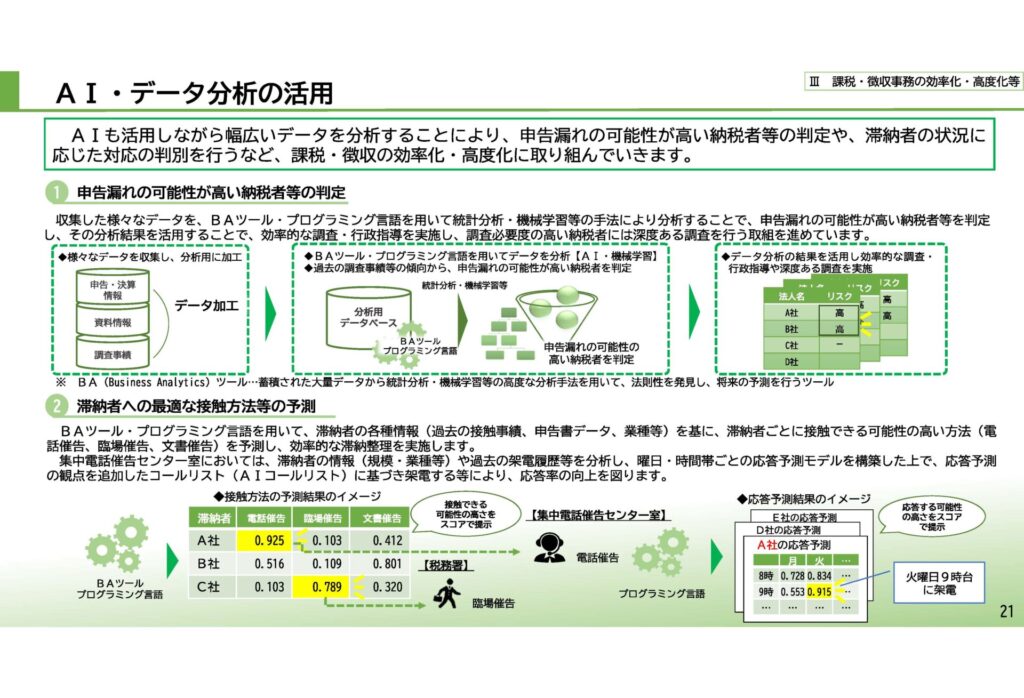
国税庁が利用するAIの詳細については公開されていませんが、ここでは、大量の確定申告の事績や過去の調査事績などのデータを入力し、ここからコンピューターが過少申告とそれ以外の申告を区別するパターンやルールを自動的に発見し、その後は、アルゴリズムが求める特定の納税者に係る情報等を入力すると過少申告のリスクの程度について、統計的・確率的な予測を示すというような機械学習アルゴリズムを想定します。
人間があらかじめ予測のための関数を用意する必要はありません。
国税庁の調査選定システムにAIを実装した場合の法的問題点
データの過誤・信頼性問題、差別・バイアス問題、セグメントに基づく予測問題、ブラックリスト問題、透明性・ブラックボックス問題、自動化バイアス・依存問題、偽陰性と偽陽性に関する問題などが存在
個人の尊重、幸福追求権、平等原則を基本原理として掲げる憲法13条や14条、あるいは適正手続を保障する憲法31条や84条などへの抵触問題に発展する可能性あり
以下、いくつかピックアップして説明します。
バイアスのある学習用データの影響
調査対象者が国税庁からみて税金を取りやすい、すなわち調査に協力的な又は当局に従順な納税者集団に偏る一方、国税庁からみて税金を取りにくい、すなわち反社会勢力、権力者、税務調査に非協力といった納税者集団は調査対象として選定されにくい、という結果をもたらす可能性があります。
過去の調査データに大きく依拠するようなアプローチは、“期ズレ”など古典的な非違の発見は得意だが限界もあるでしょう。
例えば、新規性の高い業種・業態を営む納税者や新設の法令に関わる税務調査に関していえば、不正や申告誤りの兆候を示すアルゴリズムを発見するためにセットされるデータが不足しているため、AIによる調査必要度の判定や調査必要項目の開示等が困難になる可能性があります(※1)。
直感やひらめきによって、手元にデータの蓄積がなくとも一応の判断を即座に行うことができるという人間の強みを生かした選定等も必要とされる場面があるかもしれません(※2)
(※1) David Freeman Engstrom & Daniel E. Ho, Algorithmic Accountability in the Administrative State, 37 Yale J. on Reg. 800, 821 (2020)は、タックスシェルターの例を挙げつつ、アルゴリズム執行ツールを使用している機関にとっての課題は、新しい形態の不正行為を捕捉するために、これをどのように継続的かつ反復的に更新していくかという点にあることを指摘しています。
(※2)機械とは対照的に、人間は、わずかなデータで驚くべき予測能力を発揮することがあり、例えば、一度か二度しか見たことがない顔を、別の角度からでも認識できることについて、アジェイ=アグラワルほか〔小坂恵理訳〕『予測マシンの世紀』80~81頁(早川書房2019)参照。また、データがほとんどない状況での予測について、同書128頁も参照。
バイアスの再現とエコーチェンバー現象、差別の問題
問題含みの学習用データを使用して生成された調査優先度を判定するアルゴリズムは既存のバイアスを再現し、ひいては不当な差別や偏見につながる可能性があります。
これに依拠して調査先の選定がなされ、バイアスのかかったデータ収集がなされ、よりバイアスが強くなったり、延々と繰り返されうる。学習用データに存在するバイアスが、アルゴリズムを通じて再現されるにとどまらず、選択バイアスと確証バイアスのループにより(※1) 、延々と繰り返され、エコーチェンバー現象(※2)のようにバイアスの程度が濃縮されていく可能性があります。
(※1)See Kristian Lum & William Isaac, To Predict and Serve?, SIGNIFICANCE Vol.13(5) (2016), at 16
(※2)エコーチェンバー現象について、キャス・サンスティーン〔伊達尚美訳〕『#リパブリック』(勁草書房2018)参照。
①税務調査において、特定の業種の事業を営む法人で、かつ、その代表者が特定の国籍を有しているものについて、法人税や消費税の申告に関して不正行為を行っている事例を複数把握
②当局は、当該業種の事業を営む法人で、かつ、その代表者が当該国籍を有しているものについては、同様の不正行為を行っている可能性が高いとして、類似の法人に対して、全国的に優先的かつ深度ある調査する方向性を打ち出し、多くの調査日数・人材を注ぎ込み、大量のデータを収集
③その後も、特定の国籍を有する個人や当該個人が代表者となっている法人は不正行為を行っているというイメージが先行し、同様に、調査対象として選定される確率が上昇し、実際に多くの調査が実施
④これらの調査においては、時として、担当調査官がノルマ的なプレッシャーなどから無理に不正取引の認定を行ったり、調書に多少の脚色を施したりすることもあったとする
⑤結果として、調査優先度の判定、コンプライアンスリスクの判定の際に個人や代表者の国籍を重視する、あるいは特定の国にフラグを立てるようなアルゴリズムが生成
⑥当該アルゴリズムによる選定結果は、当然ながら調査官の経験とよく適合。よって、調査官は当該アルゴリズムに共感し、これに従って調査選定し、調査を実施。それなりに結果が伴うこともあれば、時には強引な認定・処分等も行われる
上記のように、構造上、アルゴリズムによる調査選定が採用されやすくなり、そこにますます限りある調査資源が集中投下され、その調査結果がアルゴリズムにフィードバックされ、取り込まれて、一種の共鳴現象のように、バイアスが強くなり、繰り返されていくことになりはしないかという疑念があります。人が自動化されたもの、AIなどに従いやすい、自動化バイアスにも配意する必要があるでしょう。
歴史的に見て、仮に、当局に従順な納税者、税理士非関与の納税者、日本の税制に明るくない外国人の納税者など、当局から見て“税金をとりやすい納税者”から徴税を行っていたようなことがあったとすれば 、そのような状況が延々と続くおそれがあります。
元々の調査選定や調査処理に問題がなかったかを十分に調査すべきであるし、そのような問題があることを十分に踏まえて、アルゴリズムの生成を進める必要があると考えます。
アルゴリズムによる判断が統計的に見れば合理的な推論に基づいているとしても、元々のデータに誤りや偏見が含まれ、それがアルゴリズムによって再現ないし増幅され、個々の納税者がその属性等により一般化・類型化された上で、調査優先度が高い者、コンプライアンスリスクが高い者であると判断され続ける可能性があることを無視してはいけません。
データに含まれる誤りについてはその存在を把握し、これを是正する機会が納税者に確保されるべきではないか(ブラックボックス問題も参照)、上記の例のように、納税者の国籍を重視して調査先として選定することは不合理な差別として問題視されるべきかなど、検討すべき点が見えてきます。
そもそも、納税者の特定の属性を重視して調査対象として選定することは不合理な差別として問題視されるべきか、調査選定の段階で重視されるにとどまるのであれば許容されるべきか。どのような属性が問題となりうるのかといった点はこれまで十分に議論されてきませんでした。
人間の調査官による選定理由として想定され、かつ、議論の余地がありそうなもの:
法人名又は個人名、本店所在地又は居住地域、業種又は業態、性別、年齢、趣味、人種、国籍、居住者又は非居住者、身体や疾病の状況又は健康状態 、従順度(税務調査に対する協力度合い等)、宗教又は思想上の信条 、家族関係・婚姻歴・離婚歴、交友関係・異性関係 、取引先や取引金融機関、取引先に占める個人事業者の割合、関与税理士等、などがある(納税者本人限らず、親族や先代の不正行為の履歴 を含むこれらに関する属性も)
国税庁には、過去の調査資料・尾行調査資料・内定調査資料・SNS収集資料のほか、障害者・医療費・寄附金控除資料などがありますし、例えば納税者の国籍の情報を国税庁が直接的に保有していなくてもAIが推測することはありえます。なお、バイアスを取り除くことはどこまで可能なのかという問題もあります。
調査対象者の選択でバイアスがないことを保証し説明することは、困難かもしれない、という指摘に留意(岡村忠生「租税手続のデジタル化と法的課題」ジュリスト1556号58頁(2021)
ブラックリスト化問題
AIが、過去の調査データに基づいて、特定の国の国籍を有する納税者に対して調査必要度が高いと判断するようなアルゴリズムを生成したとしましょう。すると、不正計算を行う確率という観点から、特定の国の国籍を有する納税者が、調査必要度の高い者としてリスト化され、ひいてはブラックリスト(ウォッチリスト)化される可能性があります。
このこと自体は人間による選定でも起こりうるし、アルゴリズムの判断それ自体は差別や偏見に基づいているとはいい難い面もありますが、それでもなお、上記のようなブラックリスト化に対する懸念が消失することはありません。
これは、個人を無視して集団に入れ込んでレッテルを貼るような、セグメントに基づく統計的・確率的予測とも関わるプロファイリングがもたらす不安やリスクといってもよいでしょう。
統計的・確率的裏付けによって永遠に消すことができない、あるいはブラックボックス部分を視認できないような、例えば「逋脱を行っている確率が非常に高く、よって調査必要度の高い者又は還付を保留すべき者」といったスティグマを本人の関知しない、コントロールできないところで作り出す可能性があることに対する不安やリスクです(※)
また、AIの判断に従って、特定の国の国籍を有する納税者に国税当局の調査資源が集中投下されることによって、偏ったデータがますます蓄積していく上、過去の税務調査で不正計算が把握されなかった納税者であっても、当該国籍を有している以上、確率的にみて不正取引を行っているという判断は容易には覆らない可能性があります。一度、ブラックリストに名前が掲載された場合、そのリストから削除されることは容易ではないことが想定されるのです。
ブラックボックス問題(技術と法制度)
1 技術的要因
そのアルゴリズムは、どのようにして、調査必要度の判定を行うのか。どの入力変数が重要であったのか
なぜ自分(当該納税者)が、アルゴリズムによって、調査必要度が高いと判断されたのか。どの入力変数が重要であったのか。入力変数と調査必要度との間にどのような因果関係があるか。
2 法制度的要因
行政情報公開5二~四、六柱書・イ、行政個人情報14三~五、七柱書・イ、国税庁・情報公開法審査基準、通則法74の2等
不開示の具体例として、所得税・消費税の調査選定資料につき平成19年4月16日(平成19年度(行個)答申第1号や令和2年8月3日(令和2年度(行個)答申第58号)、消費税還付保留機械チェック基準につき平成31年3月11日(平成30年度(行情)答申第474号、移転価格関係資料につき令和2年9月7日(令和2年度(行情)答申第240号)などがある。富山地裁平成17年1月12日判決(税資255号順号9887)も参照。犯則事件の場合には、純粋の刑事司法とは異なるがそれと密接に関連するものであり、情報公開法5条4号の公共の安全等に関する情報に該当する場合がありうるかが問題となること及び行政調査の手法に関する行政文書であって、その開示が法の潜脱を招くようなものは同条6号イに該当することの指摘として、宇賀克也『情報公開の理論と実務』168頁(有斐閣2005)参照
アメリカにおいて、IRSが納税者の同意なしに納税者に関する電子情報を利用する場合、国民は収集した情報を確認する手段や、調査選定の判断材料としてIRSが使用する情報に存在する誤りを修正したりすることができないことを問題視する見解が示されており(※)、わが国においても同様の議論をなしえます。
(※) Kimberly A. Houser & Debra Sanders, The Use of Big Data Analytics by the IRS: Efficient Solutions or the End of Privacy as We Know It, 19 Vand. J. Ent. & Tech. L. 817, 836 (2017)
課税庁における裁量の濫用の有無が問題となった場合に、納税者を不当に扱う課税庁の意図の有無が重要な論点となりえます。かかる場面において、ブラックボックス問題は、結果的に意図を有さないアルゴリズムが課税庁にとっての隠れ蓑になることになりはしないか、という懸念にも接続します。
ブラックボックス性について、技術的要因と法制度的要因に加えて、アルゴリズムは「最小限の透明性義務の下で運営され、利益の最大化を図る民間企業」によって実装されていることがほとんどであるという組織的要因を挙げるものとして、Guido Noto La Diega, Against the Dehumanisation of Decision-Making – Algorithmic Decisions at the Crossroads of Intellectual Property, Data Protection, and Freedom of Information, 9 Jipitec 3, 9-10(2018)。
技術的要因は、当事者のリテラシーの問題とも関わります。「opacity as technical Literacy」の存在を指摘するものとして、Jenna Burrell, How the Machine “Thinks”: Understanding Opacity in Machine Learning Algorithms, Big Data Soc. (Jan. 6, 2016)。
質問検査権の行使に関して、調査の客観的必要性や調査理由の個別具体的な開示の問題場面においても法制度的要因に基づくブラックボックス問題が立ちはだかっていると見る余地があります。
このような問題場面については、酒井克彦『裁判例からみる税務調査』97~109頁(大蔵財務協会2020)参照
偽陰性と偽陽性に関する問題
実際にはコンプライアンスリスクが低い納税者について高いと誤判定する割合である偽陽性率が高い場合
⇒ “見込み違いによる権利侵害”を数多く引き起こす
実際にはコンプライアンスリスクが高い納税者について低いと誤判定する偽陰性率が高い場合
⇒脱税犯や多額の過少申告者が、長期的に“野放し”となる可能性⇒ただし、成果が出ないとして自然淘汰?成果を求めて、偽陽性率を閑却して偽陰性率を重視するバイアス?
一般論として調査選定の精度が高まること自体は歓迎します。だからといって、アルゴリズムの生成に当たって、偽陽性の割合や弊害を軽視し、偽陰性の割合を低く抑えることのみを重視するという方針を採用すべきではないでしょう。
例えば、施設内に放置された不審物の発見のアルゴリズムであれば偽陰性の割合を低く抑えることに傾注するような方針を採用することが認められるかもしれませんが、権利侵害の危険がより深刻となる場面においては、偽陽性の割合を低く抑えるよう細心の注意を払うべきです。
手続的保障の原則や納税者の権利保護を考慮して、偽陽性の割合を低く抑えることを重視するという方針を明示的に採用すべきですが、この点に関する国税庁の方針は明らかではありません。
議論の参考として、Sandra G. Mayson, Bias in, Bias out, 128 YALE L. J. 2218 (2019)参照。また、IRSが現在使用している不正検知システムの1つであるReturn Review Program(RRP)の偽陽性率と他のシステムの偽陽性率を比較したものとして、TIGTA, The Return Review Program Increases Fraud Detection; However, Full Retirement of the Electronic Fraud Detection System Will Be Delayed, Reference Number: 2017-20-080(Sep. 25, 2017)参照
本稿における結論
国税庁は、税務行政におけるAIの利用を進めるに当たり、「人間中心のAI社会原則」と「AI利活用ガイドライン」に定められている各原則を遵守し、上記で挙げた法的問題に関するものを含む納税者の権利に悪影響を及ぼす可能性の認識と対応方針等を明らかにしなければならないと考えます。
AIや機械学習アルゴリズムの利用に伴う重要な法的問題を解決できないのであれば、利用しないことも選択肢の1つになるはずです。